PG 故障模拟测试
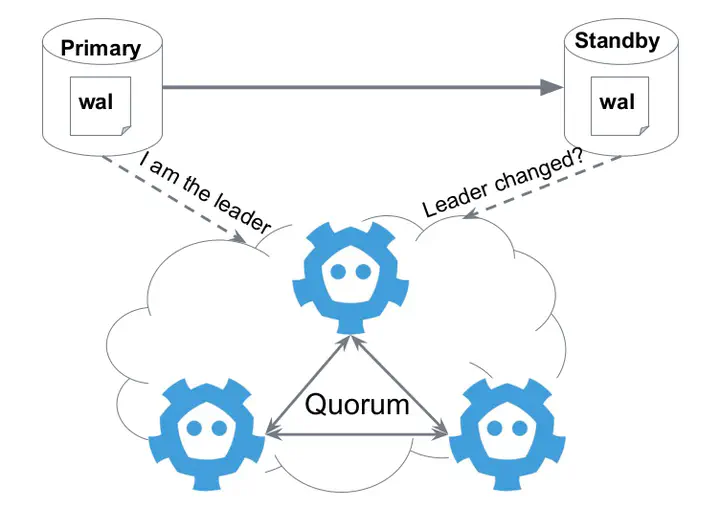
前言
在前文 PostgresQL 高可用安装中 我们创建了一个理论上高可用的 PG 数据库集群,此数据库采用 keepalived + haproy 这中传统的高可用负载均衡架构方案,也是 patroni 官方推荐的一种高可用架构。在数据层面我们采用一主两备,由 patroni 接管数据库控制权限的高可用架构。此种高可用架构在生产中运行一年多之后实际的表现如何?接下来我将实际使用的优缺点详细介绍一下。
使用情况
先说结果,上述高可用架构数据库在使用近两年的时间里未发生过一起生产故障。但是也在使用过程中发生过一些小问题,总体来说数据库运行情况良好,架构上也能满足大多数高可用需求,大家可以进行抄作业了。
接下来我会将实际的使用情况进行详细说明。
现场使用情况基本与PostgresQL 高可用安装中一文中描述一致,实际配置信息有所差异,现场采用三台物理机进行部署的,具体的物理机调优是参考 pigsty 大佬做的一些优化处理。经过调优后单台物理机单查询能达到 100 万,经过 haproxy 之后性能基本要减半,但这也基本能符合我们现有的使用情景。除此之外生产环境所有节点采用 nfs 共享存储的方式挂载归档目录,所有归档存入 nfs 中(可以考虑存入对象存储中),但也引入另外一个小问题,创建数据库时 wal-segsize 默认情况下是 16M,在大量 wal 日志下,会产生巨量的归档文件数,因此在创建数据库时可以考虑将 wal-segsize 设置成 64M,相对减少巨量文件数带来的问题。
在上线使用至今,物理机未曾重启过,数据库服务有过一些重启, DCS 在前期时未曾有过多的关注,以为只是保存个配置,数据量不大所以基本不会出现问题。但是实际上却发生了服务中断的问题,问题分析见 ETCD No Space Error,具体原因为 patroni 不停的更新主备心跳信息,从而导致产生大量的 revision ,而 etcd 在启动时未设置自动压缩(compact),从而导致 ETCD 的 KEYSPACE 爆满(默认情况下 etcd 的 DB SIZE 是 2G),最终导致 DCS 失效。在后续修复过程中也发现另外一个问题,使用 systemctl 停止 ETCD 服务时,patroni 会同样收到停止信号从而停止整个数据库(后排查得知 patroni 的 system 服务中依赖 etcd, Requires=etcd.service,需要删除,patroni 依赖 etcd 但并不依赖本地 etcd)。
高可用故障测试
Keepalived 高可用测试
| 类型 | 描述 | 操作 | 结果 |
|---|---|---|---|
| 进程故障 | 主节点进程退出 | killall keepalived | VIP 自动转移至备机 |
| 进程故障 | 主节点进程退出 | systemctl stop keepalived | VIP 自动转移至备机 |
| 进程恢复 | 主节点进程恢复 | systemctl start keepalived | VIP 自动恢复至主机 |
| 进程故障 | 备节点进程退出 | killall keepalived | VIP 主机不受影响 |
| 进程故障 | 备节点进程退出 | systemctl stop keepalived | VIP 主机不受影响 |
| 进程恢复 | 主节点进程恢复 | systemctl start keepalived | VIP 主机不受影响 |
| 网络故障 | 主节点中断网卡 | ifdown eth0 | VIP 切换至备机,各服务均正常运行,patroni 节点下线,数据库主节点故障自动转移至备节点,etcd 节点掉线,主节点重新选举 |
| 网络恢复 | 主机网卡恢复 | ifup eth0 | VIP 切换至主机,各服务均正常运行,patroni 节点上线,原数据库主节点切换至备节点,etcd 节点上线,原主节点切换成备节点 |
| 网络故障 | 备机中断网卡 | ifdown eth0 | VIP 主机不受影响,各服务均正常运行,patroni 节点下线,数据库主节点故障自动转移至备节点,etcd 节点掉线,主节点重新选举 |
| 网络恢复 | 备机网卡恢复 | ifup eth0 | VIP 主机不受影响,各服务均正常运行,patroni 节点上线,原数据库主节点切换至备节点,etcd 节点上线,原主节点切换成备节点 |
Haproxy 高可用测试
| 类型 | 描述 | 操作 | 结果 |
|---|---|---|---|
| 进程故障 | 主节点进程退出 | killall haproxy | VIP 切换至备机,haproxy 服务异常,数据库连接正常 |
| 进程故障 | 主节点进程退出 | systemctl stop haproxy | VIP 切换至备机,数据库连接正常 |
| 进程恢复 | 主节点进程恢复 | killall haproxy | VIP 切换至主机,haproxy 服务恢复,数据库连接正常 |
| 进程故障 | 备节点进程退出 | killall haproxy | haproxy 服务异常 |
| 进程故障 | 备节点进程退出 | systemctl stop haproxy | haproxy 服务异常 |
| 进程恢复 | 备节点进程恢复 | killall haproxy | haproxy 服务恢复 |
| 网络故障 | 主节点中断网卡 | ifdown eth0 | 同 keepalived |
| 网络故障 | 备节点中断网卡 | ifdown eth0 | 同 keepalived |
Etcd 高可用测试
| 类型 | 描述 | 操作 | 结果 |
|---|---|---|---|
| 进程故障 | 主节点进程退出 | killall etcd | etcd 节点重启,etcd 主节点正常,patroni、数据库正常 |
| 进程故障 | 主节点进程退出 | systemctl stop etcd | etcd 节点下线,主节点故障转移,patroni、数据库正常 |
| 进程恢复 | 主节点进程恢复 | systemctl start etcd | 原主节点切换成从节点 |
| 进程故障 | 备节点进程退出 | killall etcd | etcd 节点重启,etcd、patroni、数据库正常 |
| 进程故障 | 备节点进程退出 | systemctl stop etcd | etcd 节点下线,etcd、patroni、数据库正常 |
| 进程故障 | 二节点退出 | systemctl stop etcd | etcd 集群异常,patroni 进入只读模式, 35432 可写端口异常,35433 端口可读 |
| 进程故障 | 一主一备节点退出 | systemctl stop etcd | etcd 主节点故障转移、集群异常,patroni 进入只读模式, 35432 可写端口异常,35433 端口可读 |
| 网络故障 | 主节点中断网卡 | ifdown eth0 | etcd 节点下线,etcd 主节点故障转移,patroni、数据库正常 |
| 网络故障 | 备节点中断网卡 | ifdown eth0 | etcd 节点下线,etcd、patroni、数据库正常 |
Patroni 高可用测试
| 类型 | 描述 | 操作 | 结果 |
|---|---|---|---|
| 进程故障 | 主节点进程退出 | killall patroni | patroni 服务重启、postgres 触发主从切换,故障自动转移,VIP 数据库连接正常 |
| 进程故障 | 主节点进程退出 | systemctl stop patroni | patroni、postgres 关闭,触发主从切换,VIP 数据库连接正常 |
| 进程恢复 | 主节点进程恢复 | systemctl start patroni | patroni、postgres 恢复,原主节点切换成从节点 |
| 进程故障 | 备节点进程退出 | killall patroni | patroni 服务重启,VIP 数据库连接正常 |
| 进程故障 | 备节点进程退出 | systemctl stop patroni | patroni、postgres 关闭,VIP 数据库连接正常 |
| 进程故障 | 二备节点进程退出 | systemctl stop patroni | patroni 主 35432 端口可读写, 35433 只读端口不可用 |
| 进程故障 | 一主一备节点进程退出 | systemctl stop patroni | patroni 故障自动转移, 35432 端口可读写, 35433 只读端口不可用 |
| 网络故障 | 主节点中断网卡 | ifdown eth0 | 数据库故障转移,各服务正常 |
| 网络恢复 | 主节点网卡恢复 | ifup eth0 | 数据库故障转移,postgres 原主节点切换成从节点 |
| 网络故障 | 备节点中断网卡 | ifdown eth0 | patroni 节点下线,数据库服务正常,各服务正常运行 |
| 网络恢复 | 备节点网卡恢复 | ifup eth0 | patroni 节点上线 |
Postgres 高可用测试
| 类型 | 描述 | 操作 | 结果 |
|---|---|---|---|
| 进程故障 | 主机进程退出 | killall postgres | patroni 触发 crashed 并重启 postgres,但未发生故障转移,数据库短暂不可用 |
| 进程故障 | 备机进程退出 | killall postgres | postgres 触发重启 |
| 网络故障 | 主机中断网卡 | ifdown eth0 | 同 patroni |
| 网络故障 | 备机中断网卡 | ifdown eth0 | 同 patroni |
总结
经上述测试验证总结如下:
- 1、任何一个服务或物理节点下线,不影响数据库运行,数据库可自行故障转移和恢复。
- 2、postgres 进程异常退出时,服务可自行恢复,服务可能短暂中断。
- 3、postgres 两备节点退出时,读写端口正常运行,只读端口不可用。
- 4、postgres 一主一备节点退出时,读写端口正常运行,只读端口不可用。
- 5、etcd 两节点退出时,数据库进入只读模型,读写端口不可用
同时可将数据库优化成 3 haproxy + 3 keepalived 增加 负载均衡的高可用性。